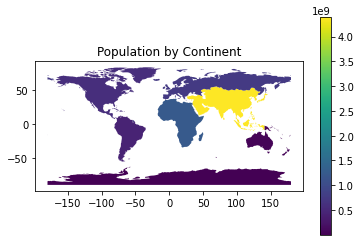
Part 0: Create Population by Continent Image¶
Use dissolve in the code cell below to create this graph.
import geopandas as gpd
import matplotlib.pyplot as plt
%matplotlib inline
gdf = gpd.read_file('ne_110m_admin_0_countries.shp')
# Filter down to just the columns of interest
# Use the dissolve operation: dissolve(by='', aggfunc='')
# Then plot the result
gdfPart 1: Use groupby to plot population¶
We can get close to the above graph (created with a dissolve) by using groupby first. But, the groupby results in a series object. We need to add that series back to the GeoDataFrame. The goal would be to get a graph that looks like the following. Note that the country borders are present.
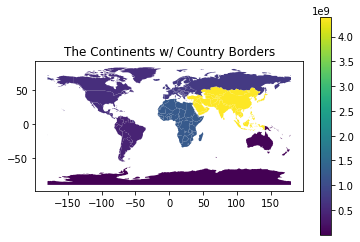
But, we have a problem...
The series won’t easily attach. This line of code doesn’t work correctly.
gdf['pop'] = pop_seriesHow do you fix this? Complete the code below.
# calculate the sum of each country to get the continent population. Returns a series
pop_series = gdf.groupby('CONTINENT')['POP_EST'].sum()
# add the series to the GeoDataFrame. There is a problem.
# First, understand what the issue is. What does this plot nothing?
# Look at what gdf['pop'] looks like. What happened to the data?
# There is a way to construct what you need. Replace this line of code.
# Hint: create a list, comprehension is useful here.
gdf['pop'] = pop_series
# Once solved, we plot the result
gdf.plot(column='pop', legend=True)
plt.title('The Continents w/ Country Borders')
Part 2A: Exploring Merge¶
Joins¶
It’s time to explore merging dataframes. In the code cell below two datasets are prepared to represent Students and Teachers. You need to practice joining the tables together in various ways.
Note: You can trim down the columns in a dataset and rename the columns as follows:
# trim to just two columns. Rename 't_name' to 'teacher'
result[['student_name', 't_name']].rename(columns={'t_name': 'teacher'})Activity¶
Create the datasets below using multiple joins
Trim the count of columns and rename them to better names
Take note of the rows with NaN and when that is better/worse
Predict which rows will be present before executing the code
Datasets:
Students and their Advisory Teachers
Teachers with their TAs
import pandas as pd
# This just sets up the datasets (aka: tables or dataframes)
st_data = { 'student_name': ['Nikhil', 'Cassie', 'Juliette'],
'student_id': [ 1, 2, 3],
'advisory_teacher_id': [ 2, 4, 5]}
students = pd.DataFrame(data=st_data)
teacher_data = { 't_name': ['Rukman', 'Harrison', 'Olsen', 'Teachout', 'Seeley'],
't_id': [ 1, 2, 3, 4, 5],
'ta_student_id': [ 1, 3, 3, 0, 1]}
teachers = pd.DataFrame(data=teacher_data)
display(students)
display(teachers)# create a table of student names with the names of their advisory teacher
# create a table of Teachers with their TAs
Part 2B: Same thing...¶
Join Types¶
In the code cell below, the datasets are slightly modified so that you can see how the joins work when there are multiple keys in the right dataset. Practice doing all types of joins.
# to see a left join with a repetition, let's change the data a bit
# create a TA_GROUP and students belong to the TA_GROUP
st_data = { 'student_name': ['Nikhil', 'Cassie', 'Juliette'],
'student_id': [ 1, 2, 3],
'advisory_id': [ 2, 4, 5],
'ta_group_id': [ 1, 2, 1]}
students = pd.DataFrame(data=st_data)
teacher_data = { 't_name': ['Stride', 'Harrison', 'Olsen', 'Teachout', 'Seeley'],
't_id': [ 1, 2, 3, 4, 5],
'ta_group_id': [ 1, 2, 0, 1, 1]}
teachers = pd.DataFrame(data=teacher_data)
# join the tables together again and note the resultsPart 3: Use Join after groupby¶
Join Types¶
Above we did a groupby to get a series object and then added it to the GeoDataFrame before plotting it. In order to add it, we created a list of the correct length with the correct data. But now we have more tools available to us. We can do a merge (join) to add the series to the GeoDataFrame.
Complete the code below to generate the same graph as above.
ERROR: The merge works great. ARRG!! The plot fails. Yes, I set you up for this failure. But, you are now tasked to fix it. First, try to understand the error. Investigate by printing stuff. Then, implement your favorite fix... there are at least 3.
import geopandas as gpd
import matplotlib.pyplot as plt
%matplotlib inline
gdf = gpd.read_file('ne_110m_admin_0_countries.shp')
# get a series that groups by the population
# calculate the sum of each continent. Returns a series with 7 rows (1 per continent)
pop_series = gdf.groupby('CONTINENT')['POP_EST'].sum()
# Filter down to just the columns of interest since merge works on all columns
populations = gdf[['POP_EST', 'CONTINENT', 'geometry']]
# Do a join to generate a new dataframe
final = populations.merge(...)
# Then plot the result
final.plot(column='POP_EST', legend=True)
plt.title('The Continents w/ Country Borders')
Part 4: Affected States¶
Hurricane Florence - sjoin¶
For Hurricane Florence, a plot of the affected states is drawn. Run the code cell below to see what it looks like.
Activity : Understand and Explain¶
All of the code is provided for you in the Code Cell below. Answer the following questions:
Question #1A: When creating the affected_states why is inner the correct join? Explain why left and right are incorrect.
answer goes here
Question #1B: How many rows are in the dataset affected_states? Is there any benefit to reducing the dataset so that each state appears only once? Can you figure out a way to do this correctly?
answer goes here
Question #2: Why is it necessary to create a figure with the API subplots?
answer goes here
Question #3: What is the purpose of plotting the country with color='#EEEEEE'?
answer goes here
Question #4: What happens when you reverse the order of these two plots? Why does that happen?
answer goes here
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
from shapely.geometry import Point
%matplotlib inline
# Load in US Data
country = gpd.read_file("gz_2010_us_040_00_5m.json")
country = country[(country['NAME'] != 'Alaska') & (country['NAME'] != 'Hawaii')]
# Load in Florence data
florence = pd.read_csv('stormhistory.csv')
florence['coordinates'] = [Point(-long, lat) for long, lat in
zip(florence['Long'], florence['Lat'])]
florence = gpd.GeoDataFrame(florence, geometry='coordinates')
# Advanced: Need to specify map projection points so we can join them later
florence.crs = country.crs
# Do a Spatial Join on the two datasets
# It is a static method in the GeoPandas module
# Code related to questions #1A and #1B:
affected_states = gpd.sjoin(country, florence, how='inner', predicate='intersects')
# Code related to question #2:
fig, ax = plt.subplots(1, figsize=(20, 10))
# Code related to question #3
country.plot(ax=ax, color='#EEEEEE', edgecolor='#FFFFFF')
# Code related to question #4
affected_states.plot(ax=ax, edgecolor='#FFFFFF')
florence.plot(ax=ax, color='#000000', markersize=10)